 BeMined
BeMined
Text Mining
To transform Big Data into value, in other words into Smart Data, storing and processing of the data semantics and metadata is essential. Text mining (TM), also referred to as text data mining, is the process of deriving high-quality information from text. Text mining usually involves the process of structuring the input text, deriving patterns within the structured data, and finally evaluation and interpretation of the output.
The overarching goal is, essentially, to turn text into data for analysis, via application of natural language processing and analytical methods.
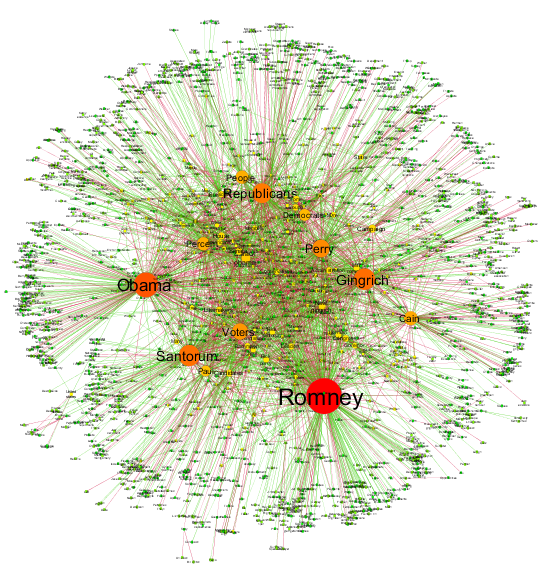
Narrative network of US Elections 2012
Vector space models
Suppose we have a collection of documents and need to analyze them in terms of similarity. One of possible TM approaches is to represent each document by a vector reflecting information on occurrences of different terms (words) in this document. In the next step, this vector is typically mapped into another vector space by some mapping P, where some additional information, e.g. word informativity, can be taken into consideration.
Every P defines another Generalized vector space model (GVSM). The simplest case involves linear transformations, where P is any appropriately shaped matrix.
The Basic Vector Space Model (BVSM) uses the vector representation with no further mapping, i.e. P = I in this case. According to the BVSM, a document is represented by a column vector, where each entry is the frequency of some term in the given document. Therefore, the corpus of documents can be represented by a “term by document” matrix D, where each column corresponds to some document from corpus and each row corresponds to some term from vocabulary (a set of all distinct terms in the whole corpus).
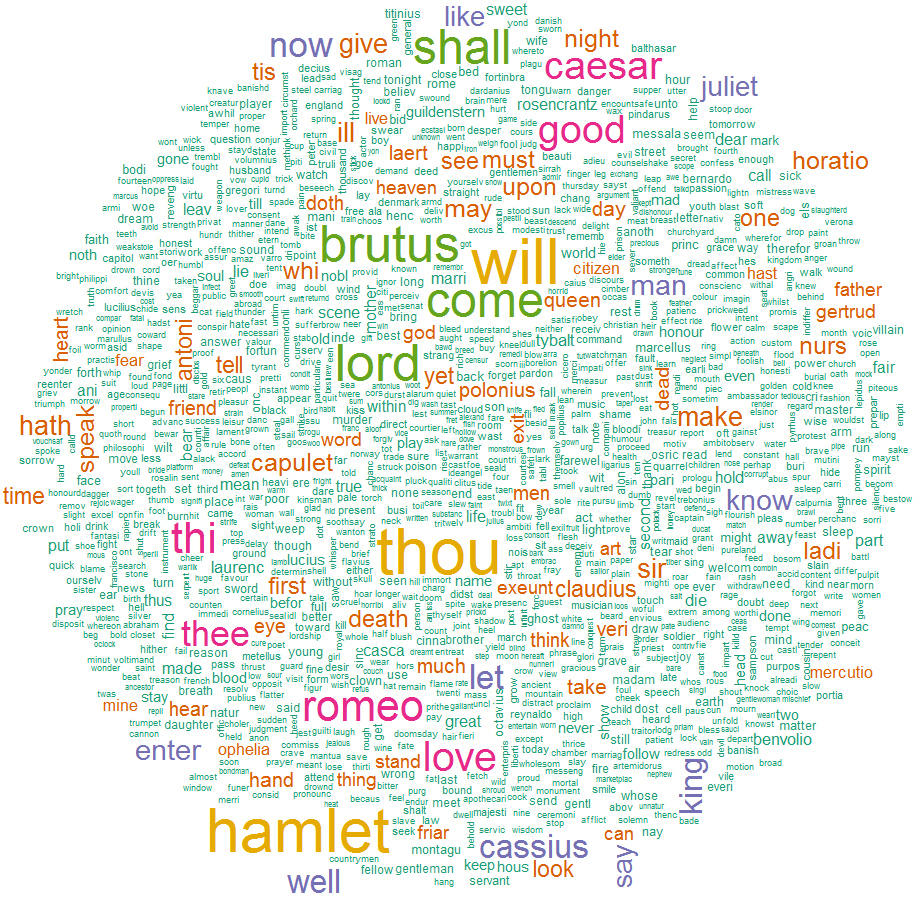
Word cloud of all words in 3 Shakespeare’s tragedies: Hamlet, Julius Caesar, Romeo and Juliet
The Term-Term Correlations Model, also referred to as GVSM(TT), is a particular case of GVSM with linear mapping P = DT. In this model terms become semantically related if they co-occur often in the same documents. If the BVSM represents a document as bag of words, the GVSM(TT) represents a document as a vector of its similarities relative to the different documents in the corpus.
Other models based on and extending the vector space model include: Latent semantic analysis (LSA), Term Discrimination, Rocchio Classification, Random Indexing and others. More information on the BVSM, GVSM and LSA models may be found in Q3-D3-LSA (Borke and Härdle, 2017).
Latent semantic analysis
Latent semantic analysis (LSA) is a technique to incorporate semantic information in the measure of similarity between two documents. In this approach the documents are implicitly mapped into a semantic space where documents that do not share any terms can still be close to each other if their terms are semantically related. LSA measures semantic information through co-occurrence analysis in the corpus: terms that co-occur often in the same documents are considered as related and merged into a single dimension of the new space.
This statistical co-occurrence information is extracted by means of a singular value decomposition (SVD) of the term by document matrix (rows represent unique words and columns represent each document), which is used to reduce the number of rows while preserving the similarity structure among columns.
Several classes of adjustment parameters can be functionally differentiated in the LSA process. The following classes have been identified so far by Wild and Stahl (2007): textbase compilation and selection; preprocessing: stemming, stopword filtering, special vocabulary etc.; weighting schemes, dimensionality, similarity measurement.
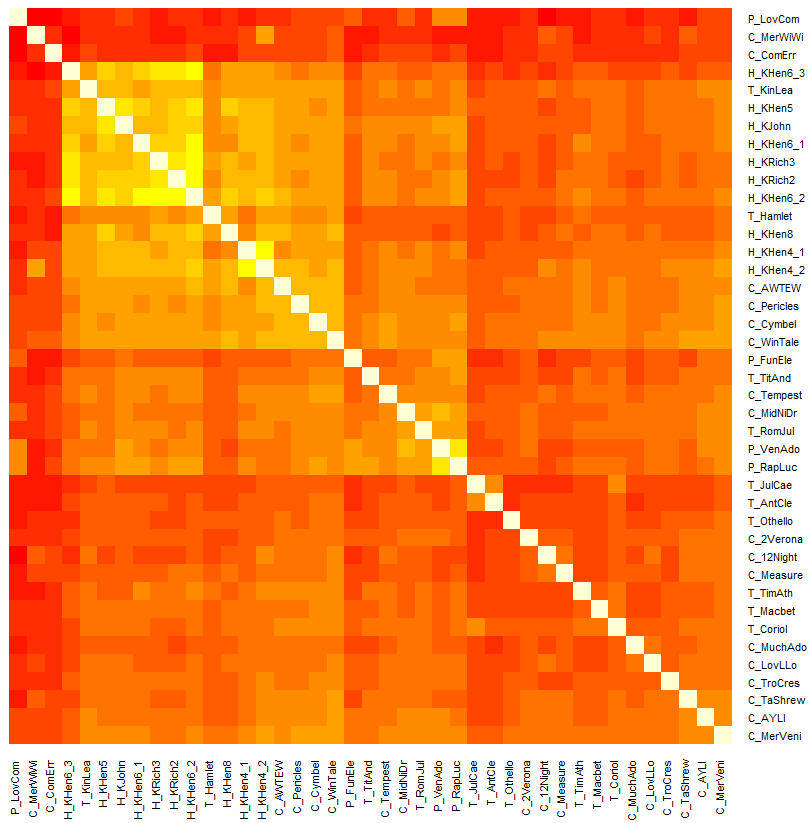
Representation of Shakespeare’s works: their similarity matrix via heat map
Text Mining with R
The overview of R packages dealing with text mining is given in the Natural Language Processing CRAN task view. We describe some of them below.
The tm package provides a comprehensive text mining framework for R enabling intelligent methods for corpora handling, meta data management, preprocessing, operations on documents, and data export. The article Text Mining Infrastructure in R gives a detailed overview and presents techniques for count-based analysis methods, text clustering, text classification and string kernels. In addition, various plugins extending the functionality of the package are available.
The lsa package provides routines for performing a latent semantic analysis with R. The article Investigating Unstructured Texts with Latent Semantic Analysis gives a detailed overview and demonstrates the use of the package with examples from the area of technology-enhanced learning.
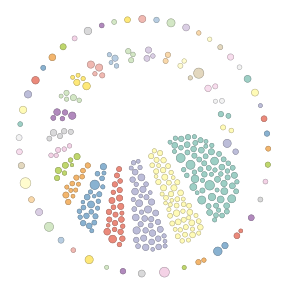
Orbit clustering of BitQuery performed by means of tm and lsa packages